Table des matières
Ce tutorial a pour objectif d'installer le plugin Derby dans Eclipse, de se connecter à une base Derby, et de lancer une première requête SQL. Il s'adresse aux utilisateurs connaissant déjà un peu Eclipse et les bases de données.
Il suppose que l'on a installé la version JEE d'Eclipse. Les captures d'écran ont été réalisées avec la version 3.7.1 d'Eclipse. Elles peuvent être différentes sous d'autres versions.
L'équipe de développement de Derby a commencé à écrire un plugin pour Eclipse, puis a abandonner ce développement, qui sortait de son champ d'activité. Le plugin Derby que l'on peut utiliser actuellement est donc toujours disponible sur les pages Apache / Derby, jusqu'à ce qu'une autre équipe le prenne en charge. La version 10.8.1.2 de ce plugin a été publiée en avril 2011, elle n'est donc pas, à l'heure où nous écrivons ces lignes, obsolète !
On peut télécharger le plugin sur cette page : http://db.apache.org/derby/releases/release-10.8.1.2.cgi. Il se compose de deux fichiers :
-
derby_core_plugin_10.8.1.zip -
derby_ui_doc_plugin_1.1.3.zip
Une fois ces deux fichiers téléchargés, il faut les ouvrir dans le répertoire d'installation d'Eclipse.
Cela aura pour effet d'ajouter trois répertoires dans le répertoire plugins d'Eclipse :
-
org.apache.derby.core_10.8.1; -
org.apache.derby.plugin.doc_1.1.3; -
org.apache.derby.ui_1.1.3.
Si Eclipse était lancé lors de la copie de ces répertoires, alors il faut le relancer.
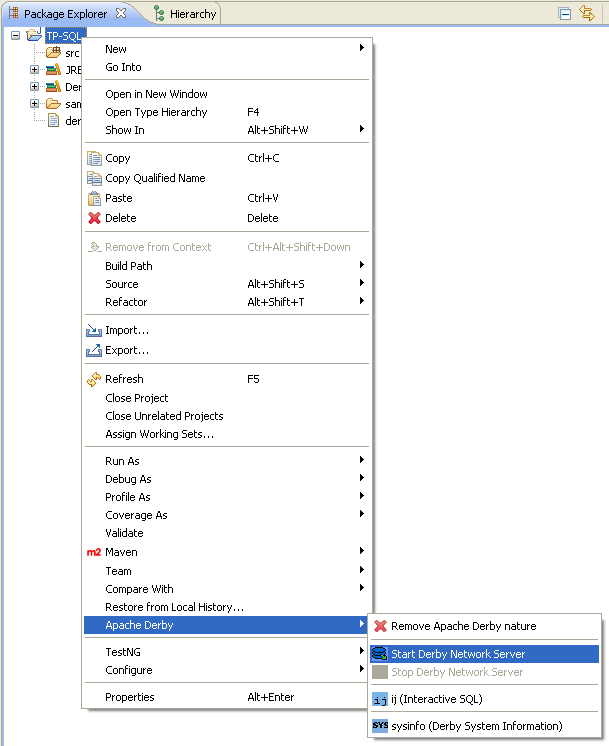
On peut interagir avec Derby à partir de n'importe quel projet Eclipse. Pour cela il faut activer sa nature Derby (car tout projet, en général sans le savoir, a une nature Derby cachée !). Cela se fait en allant chercher la bonne option du menu contextuel du projet.
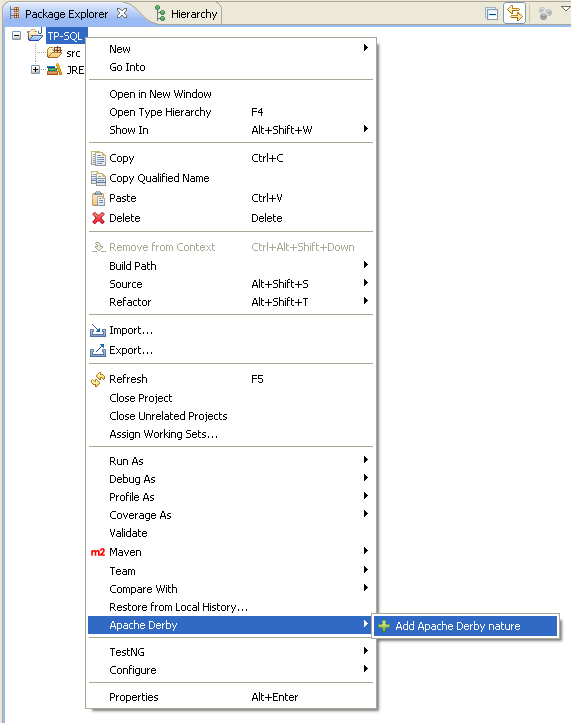
Une fois cette nature ajoutée, on doit voir les dépendances vers les bibliothèques de Derby dans le projet, comme sur la figure ci-après.
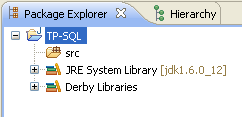
Notre projet est prêt, et va pouvoir utiliser une base Derby.
Derby est une base de données entièrement programmée en Java, que l'on peut utiliser dans deux modes.
-
Un mode embedded : Derby fonctionne dans la même JVM que l'application principale. Ce mode ne permet qu'à un seul utilisateur de se connecter à la base, ce qui est suffisant dans de nombreux cas applicatifs.
-
Un mode serveur classique : Derby écoute un port TCP, accepte des connexions dessus, et traite les requêtes au travers de ce port. Ce mode est moins performant que le premier, mais permet à de nombreux utilisateurs d'accéder au serveur en même temps.
C'est ce second mode que nous allons utiliser à présent.
Le lancement d'un serveur Derby se fait en sélectionnant la bonne option dans le menu contextuel du projet.
C'est sur la console Eclipse que s'affichent les messages d'erreur, ou qui indiquent que le serveur est correctement lancé. Il ne reste plus qu'à se connecter à ce serveur.
Notons deux choses :
-
le lancement d'un serveur Derby est indépendant du fait que l'on a créé une data source qui permet d'y accéder ;
-
on peut lancer un serveur Derby de tout projet qui posséde une nature Derby.
La connexion à un serveur Derby sous Eclipse passe par une source de données. Cette source de données est enregistrée au niveau du workspace dans lequel on travaille, il suffit donc de la créer une unique fois, et de l'utiliser à chaque fois que l'on souhaite se connecter au serveur.
La gestion des sources de données se fait dans la vue Data Source Explorer, que
l'on ouvre par le menu Windows > Show view.
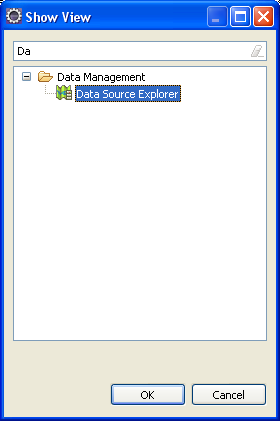
C'est à partir de cette vue que l'on peut créer des sources de données.
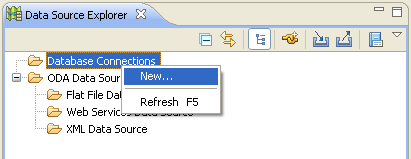
Cette option lance le wizard de création d'une source de données, qui se fait en plusieurs étapes.
La première étape consiste à choisir à quel serveur de base de données l'on va s'adresser. La plupart des serveurs sont disponibles : MySQL, PostgreSQL, Oracle, SQL Server, etc... Ici l'on choisit Derby.
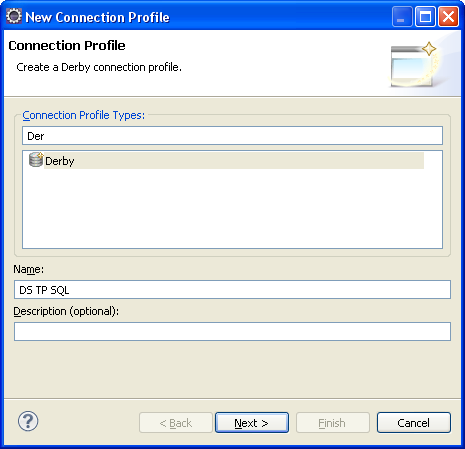
L'étape suivante dépend du serveur qui a été sélectionné. Les informations qui sont typiquement
demandées sont l'hôte et le port sur lequel se trouve le serveur de base de données, ainsi
que les identifiants de connexion : nom et mot de passe. On choisit de prendre scott
comme nom de connexion et tiger pour mot de passe, dans la grande tradition des
bases de données sérieuses.
Notons que Derby nous fait l'amabilité de créer cet utilisateur s'il n'existe pas.
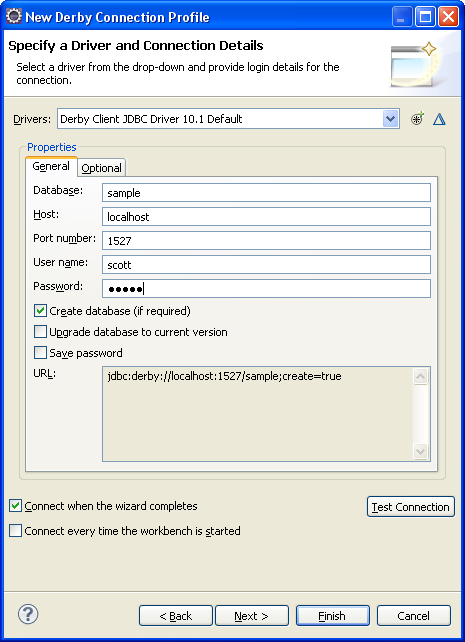
La dernière étape de cette création consiste simplement à valider les paramètres qui ont été choisis.
Cliquer sur le bouton Finish permet de lancer la création de cette source
de données.
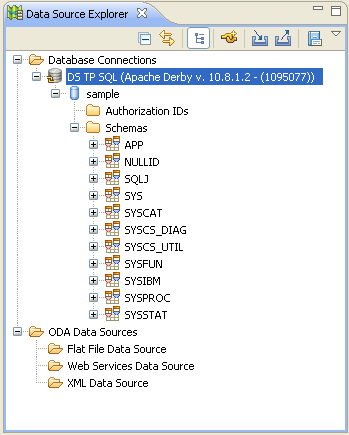
Notre source de données apparaît alors dans la fenêtre Data Source Explorer,
elle doit ressembler à la figure suivante.
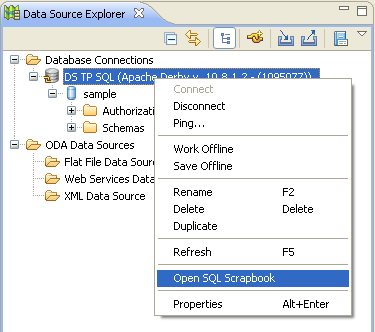
Lancer des requêtes SQL peut se faire via la vue Eclipse SQL Scrapbook. Cette
vue s'ouvre à partir du menu contextuel d'une source de données, comme sur la figure suivante.
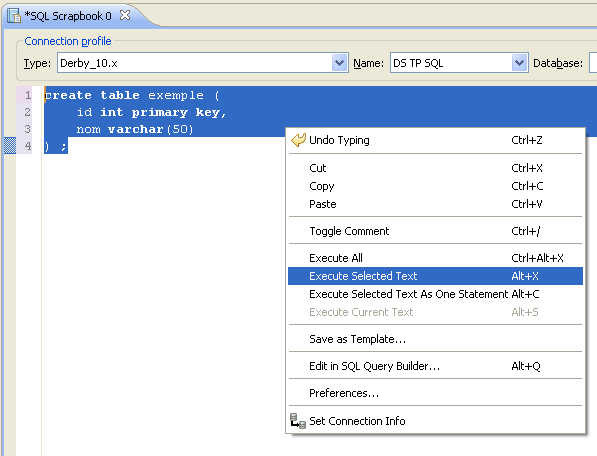
Cette vue permet de saisir des requêtes SQL en mode texte classique, avec bien sûr la coloration syntaxique Eclipse. On peut saisir autant de requêtes que l'on souhaite, et les lancer toutes ou en partie à l'aide du menu contextuel, ou de raccourcis clavier. Le contenu de cette fenêtre peut être sauvé dans un fichier, exactement comme un code source.
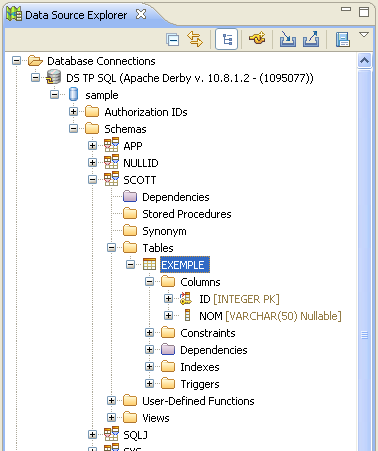
Une création de table a toujours lieu, par défaut, dans un schéma qui porte le nom de l'utilisateur
sous lequel on s'est connecté, ici Scott. De fait, si l'on rafraîchit la vue
Data Source Explorer, on voit ce nouveau schéma, et la table que l'on vient
de créer dans notre exemple.
Notons enfin que les requêtes de type select renvoient leurs résultats dans une
autre vue (qui s'ouvre automatiquement) : SQL Results. Cette vue permet d'exporter
les résultats sous différents formats, ainsi que de gérer l'historique des requêtes SQL
passées.
Cette connexion s'établit en deux temps :
-
lancement du serveur proprement dit ;
-
connexion à ce serveur, via la source de données.
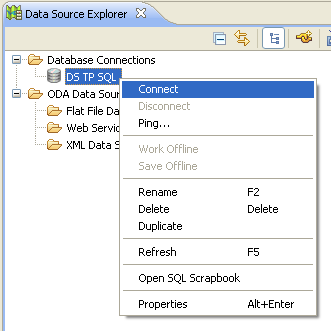
Une fois le serveur lancé, on peut connecter une source de données existante à ce serveur.
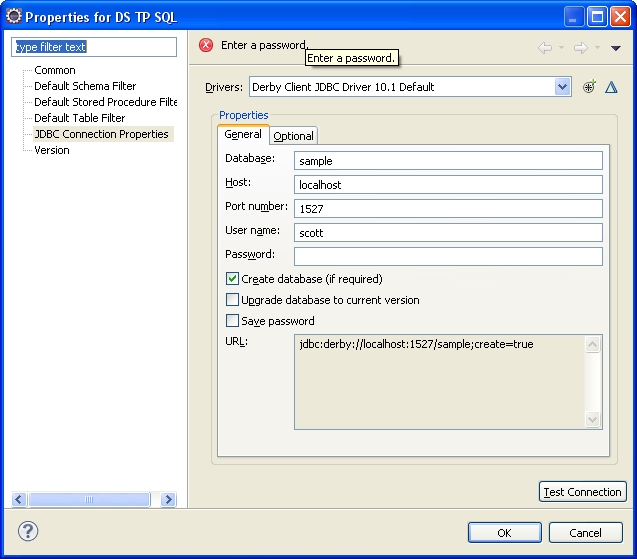
Si le mot de passe de connexion n'a pas été enregistré lors de la création de la source de données (il n'est pas conseillé de le faire !), alors il faut l'entrer à chaque connexion.
On peut ensuite lancer des requêtes SQL sur la base, en utilisant la vue SQL scrapbook, comme expliqué précédemment.