Table des matières
Ce tutorial a pour objet de présenter la configuration d'Eclipse pour développer des applications JEE (en particulier des EJB) à l'aide de Glassfish. Glassfish est un serveur JEE complet, implémentation de référence de la version JEE6. Il en existe une version gratuite et open-source. On peut le trouver à cette page : http://glassfish.java.net/.
L'installation de Glassfish ne pose pas de problème particulier, que ce soit sous
Linux ou Windows. On n'oubliera pas, une fois l'installation terminée, de télécharger
les mises à jour, en utilisant la commande updatetool disponible dans
$GLASSFISH_HOME/bin.
Un serveur d'application JEE définit la notion de domaine. L'objet de ce tutorial n'est pas de définir et d'expliquer cette notion en détails, mais disons qu'un domaine est une notion très générale, qui ressemble à un espace de travail. Un serveur Glassfish peut gérer de nombreux domaines, et toutes les applications que l'on peut déployer doivent vivre à l'intérieur d'un domaine.
Techniquement un domaine est matérialisé par un répertoire. Par défaut ce répertoire est
un sous-répertoire de $GLASSFISH_HOME/glassish/domains, mais il existe des
configurations dans lesquelles ce répertoire n'est pas accessible en écriture.
On peut donc créer un domaine Glassfish dans le répertoire courant par la commande suivante.
$ asadmin create-domain --domaindir . domaine-tutorial
L'option --domaindir peut aussi prendre un chemin absolu en paramètre.
Après un peu de bavardage, Glassfish demande un mot de passe pour le compte administrateur de ce domaine, qu'il faut noter soigneusement.
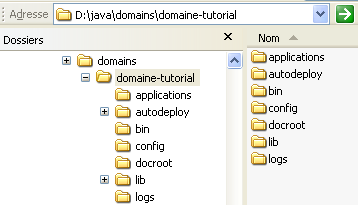
Voici la structure de répertoires d'un domaine Glassfish.
La première étape de la préparation d'Eclipse consiste à prendre en charge le serveur Glassfish au travers de son plugin. Pour cela, on déclare Glassfish en tant que runtime environment.
La liste des runtime environment est accessible via les préférences d'Eclipse.
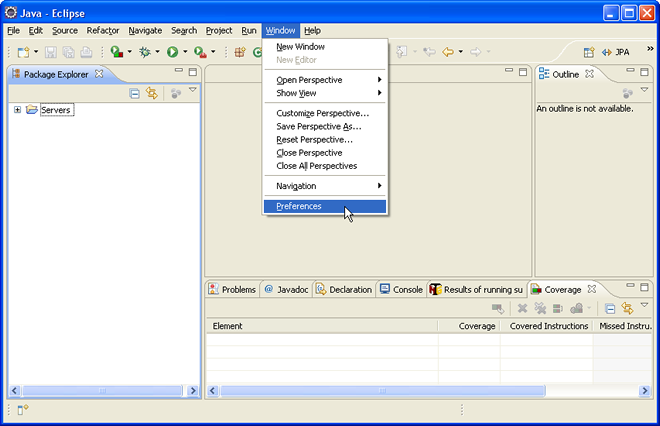
Cette fenêtre présente de nombreuses options, qu'il est possible de filtrer. L'option que l'on cherche est Server > Runtime environment.
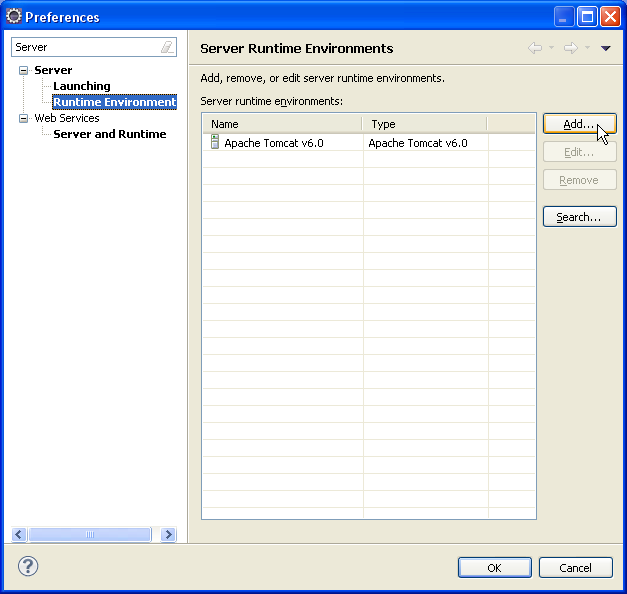
Il faut cliquer sur le bouton Add... pour ajouter un runtime environment, ce qui nous mène au panneau suivant.
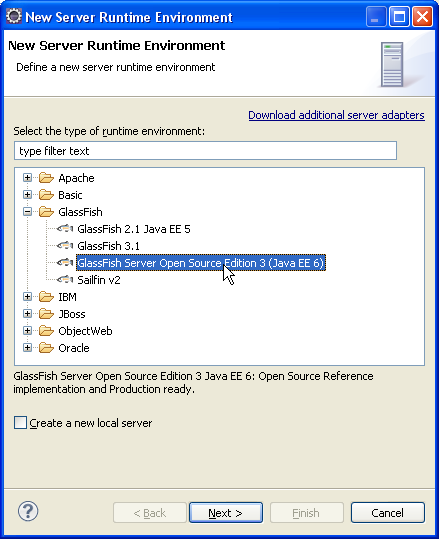
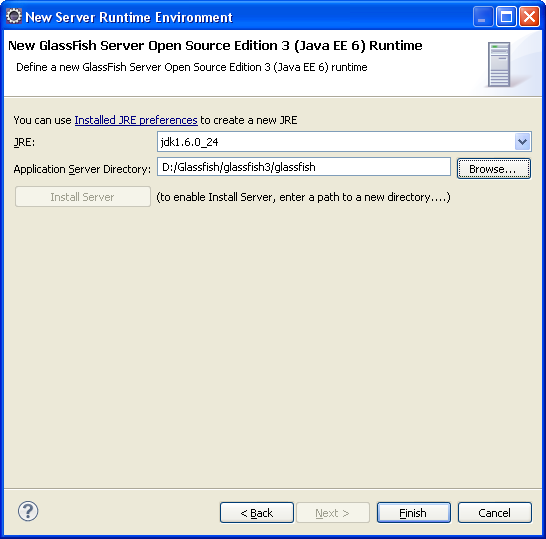
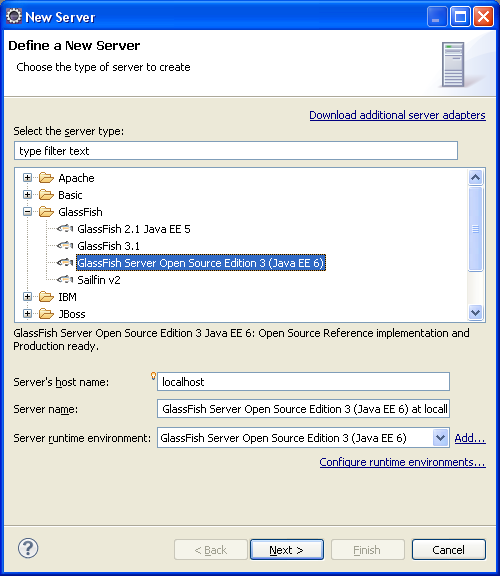
On peut alors sélectionner la bonne version de Glassfish, et accéder à la suite des panneaux de configuration.
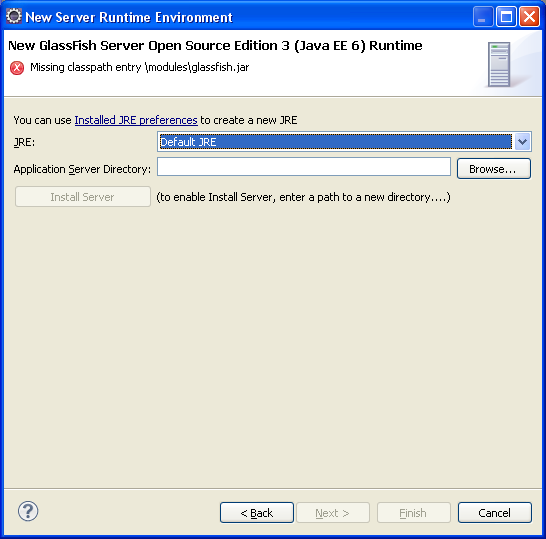
On sélectionne le bon JDK dans un premier temps.
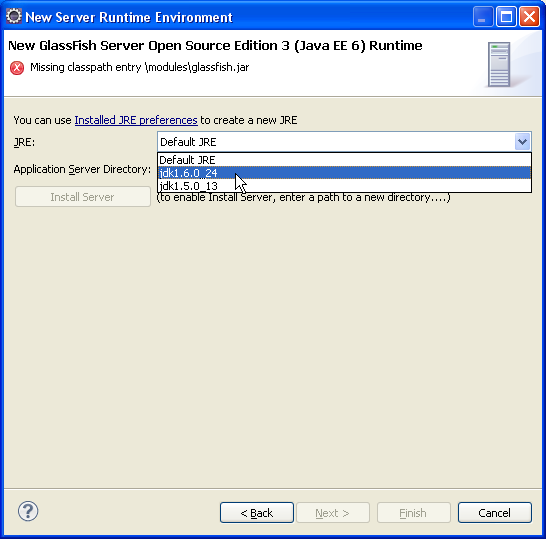
Puis on sélectionne son répertoire d'installation. Attention, le répertoire que demande
Eclipse correspond au répertoire $GLASSFISH_HOME/glassfish.
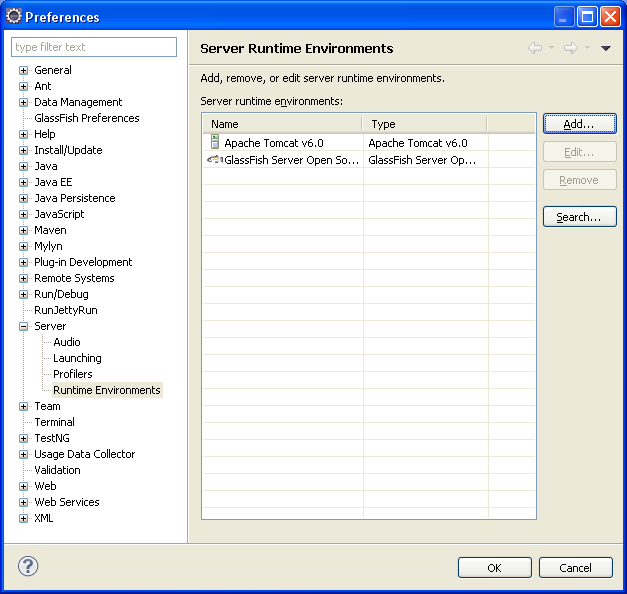
Valider l'installation fait apparaître Glassfish dans la liste des environnements d'exécution disponibles.
Glassfish permet de gérer de nombreuses choses, dont une qui va nous être immédiatement utile : une connexion à une base de données. La gestion peut se faire au travers d'Eclipse, ce qui est très pratique. Il faut pour cela ouvrir Glassfish dans Eclipse.
Pour cela, on utilise la vue Servers de la perspective JEE d'Eclipse.
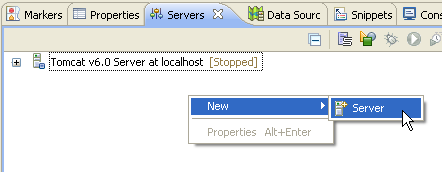
La création de ce nouveau serveur au niveau d'Eclipse nous mène au même panneau que précédemment. Cette fois Glassfish est associé à une installation, qui est sélectionnée par défaut dans le panneau.
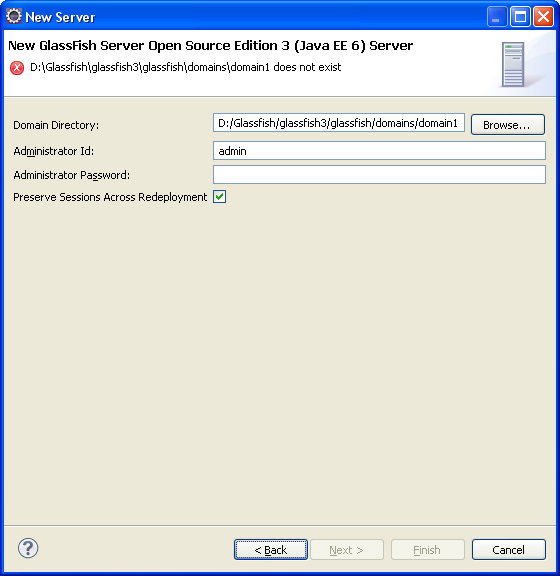
Le panneau suivant nous demande deux informations, qu'Eclipse ne peut pas deviner : le domaine que nous allons utiliser, et le mot de passe de l'administrateur de ce domaine. Comme nous avons pris la précaution de créer un domaine au préalable, nous allons pouvoir le donner à Eclipse.
Une fois le domaine correctement configuré, Eclipse ne nous donne plus de message d'erreur.
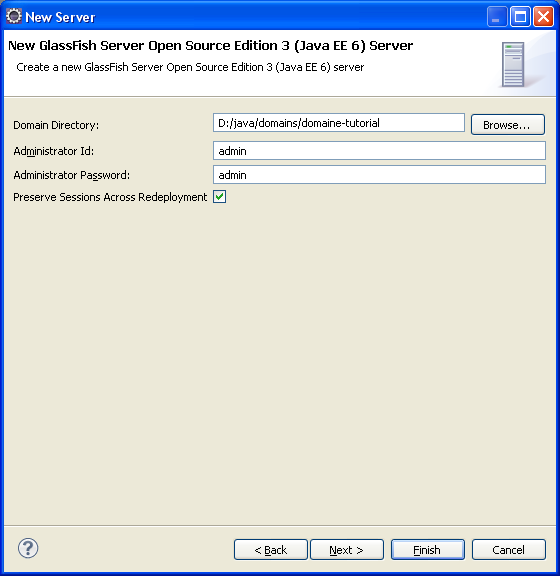
La dernière étape consiste à ajouter des projets JEE à ce domaine. Nous n'en avons pas pour le moment, la fenêtre est donc vide, et on peut la passer.
Une fois cette configuration terminée, Glassfish apparaît dans la vue Servers, aux côtés de Tomcat.
Cette partie suppose que l'on a configuré une base de données Derby en mode serveur, et que cette base de données est lancée. Pour ce faire, on peut se reporter au tutorial Premiers pas avec Derby dans Eclipse.
Glassfish est administré via une application web, qui se lance en même temps que le serveur. On se propose à présent de créer une première source de données à partir de ce panneau.
La première chose à faire est de lancer Glassfish, en cliquant sur le bouton Start.
Eclipse active la vue Console, dans laquelle apparaît la journalisation de Glassfish. Après quelques secondes, Glassfish est démarré, et l'on peut accéder à la console d'administration en chargeant l'URL :4848/. Le panneau de connexion s'affiche en quelques secondes.
J'ai constaté un bug curieux dans le couple Eclipse / Glassfish, du moins avec les versions
que j'utilise, sous Windows. Lors du lancement d'Eclipse, si le PATH comprend
des chemins avec des espaces, alors Glassfish ne se lance pas. La solution consiste pour moi
à créer un fichier le lancement (un bon vieux .bat des familles) avec un
PATH minimal, qui ne comporte pas ce défaut.
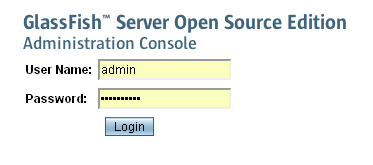
Le nom de connexion est admin, et le mot de passe est celui qui a été entré
au moment de la création du domaine.
Une fois authentifié, le panneau d'administration complet s'affiche. L'objet de ce tutorial n'est pas de détailler chacune de ses fonctionnalités. Nous allons juste l'utiliser pour créer une source de données.
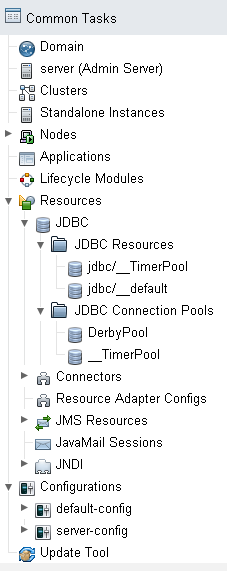
Une source de données se crée en deux temps :
-
création d'un pool de connexions JDBC (JDBC Connection Pools) ;
-
création d'une ressource JDBC, utilisant ce pool (JDBC Resources).
La création du pool se fait au travers de l'interface d'administration de Glassfish. Le nom
de ce pool ne peut pas contenir d'espaces, il faut donc prendre garde à ce point. Le
type choisi peut être javax.sql.DataSource, et dans le cas de Derby,
la classe d'implémentation sera org.apache.derby.jdbc.ClientDataSource.
Les propriétés du pool sont les propriétés JDBC classiques : identifiant de connexion et
mot de passe, nom de la base, qui doivent bien sûr correspondre aux paramètres de la base
Derby.
Si la base Derby est bien lancée, il est possible de vérifier que ce pool s'y connecte bien, en cliquant sur le bouton Ping.
La création de la source de données se fait ensuite. Il faut renseigner deux paramètres pour cette création.
-
Le nom du pool sur lequel cette source de données va s'appuyer. Ce nom est à choisir dans un menu déroulant.
-
Le nom JNDI de la source de données que l'on crée. Dans ce tutorial, le nom est
jdbc/tutorial-jee. C'est ce nom que l'on va utiliser pour connecter la partie JPA de notre application JEE à la base de données.
On peut, en suivant la même procédure, ouvrir des sources de données sur autant de bases que l'on veut, et de n'importe quel type.
Supposons que l'on ait déjà un projet JPA sous la main, avec une unique classe, Marin.
Pour créer un tel projet, on pourra se reporter au tutorial
Premier pas avec Eclipse et JPA.
Le projet JPA que l'on ajoute a la structure suivante, rien ne le différencie de celui que l'on a construit sur notre tutorial.
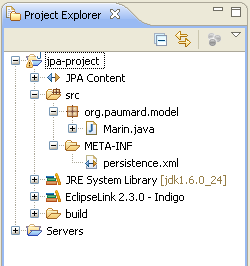
La structure de notre projet JPA n'est pas différente de celui que l'on a vu dans le
tutorial précédent. En revanche, le contexte d'utilisation est différent : il s'agit
d'un projet JEE, alors que le précédent était un projet JSE. Plutôt que de se connecter
directement à une base de données, notre unité de persistence doit utiliser la source
de données que l'on a défini précédemment. Pour cela, on doit modifier le fichier
persistence.xml
Exemple 1. Fichier persistence.xml en version JEE
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="jpa-project" transaction-type="JTA"> <!-- Eclipse link JPA implementation --> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <!-- Data source definition --> <jta-data-source>jdbc/MelodieDS</jta-data-source> <class>org.paumard.model.Marin</class> <properties> <property name="eclipselink.ddl-generation" value="drop-and-create-tables"/> </properties> </persistence-unit> </persistence>
On remarquera les différences suivantes.
-
Le
transaction-typeest fixé à la valeurJTA(Java Transaction API), cela signifie que les transactions sont gérées par le serveur JEE. -
La définition de la source de données : élément
jta-data-source. -
La disparition de la définition de la connexion directe, dans l'élément
properties.
Le code de notre classe Marin ne contient pas de points trop exotiques.
Exemple 2. Classe persistente Marin
@Entity(name="marin") @Table(name="marin") public class Marin implements Serializable { @Id @GeneratedValue(strategy=GenerationType.AUTO) private long id; private String nom; private String prenom; private int salaire; public Marin() { } public Marin(String nom, String prenom, int salaire) { this.nom = nom ; this.prenom = prenom ; this.salaire = salaire ; } // suivent les getters et les setters }
Le deuxième projet que nous allons créer va nous permettre de stocker les interfaces de nos EJB. Ce projet est un projet Java classique, qui a juste besoin de connaître les classes du projet JPA, puisque c'est là que se trouve notre modèle objet.
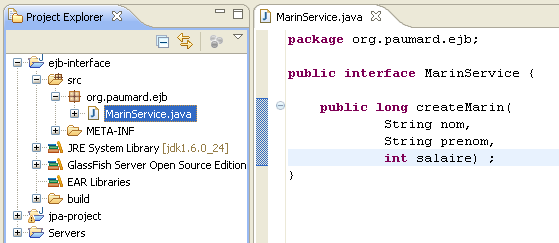
Pour l'instant on crée une unique classe dans ce projet : MarinService, qui
n'expose qu'une unique méthode.
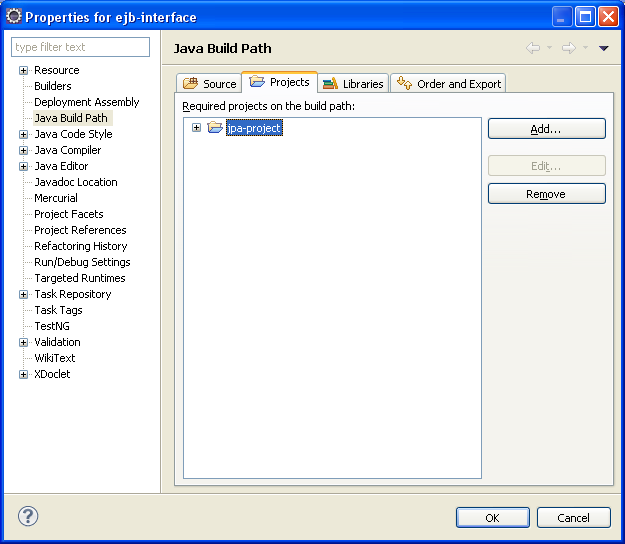
La dépendance vers le projet JPA est définie dans les propriétés de ce projet, de façon classique.
Le code de notre interface est le suivant. Il s'agit d'une interface basique, sans aucune particularité.
Exemple 3. Interface MarinService
public interface MarinService {
public long createMarin(String nom, String prenom, int salaire) ;
}
Le projet ejb-project est un projet différent, non pas dans sa structure,
mais dans ses dépendances.
Il va contenir l'implémentation de notre interface, et manipuler des objets en base. Les classes de ce projet vont donc dépendre du modèle, mais aussi des classes JEE : annotations notamment. Eclipse nous propose une manière propre de créer ce genre de projet.
Lors de la création de ce projet, on choisit le type EJB.
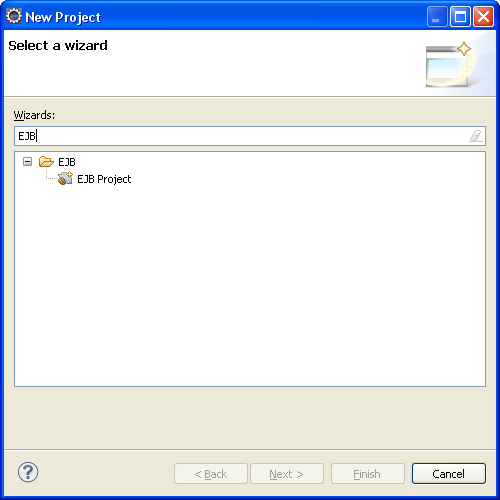
Le panneau qui suit nous permet de choisir le type de serveur qui va être utilisé pour exécuter ce projet. Il s'agit naturellement du serveur Glassfish que l'on vient de créer. L'un des intérêt est que toutes les librairies JEE sont mises automatiquement en dépendance du projet créé.
On précise de plus la version de nos EJB : ici version 3.0. Il existe aussi une version 3.1, qui est celle proposée par défaut.
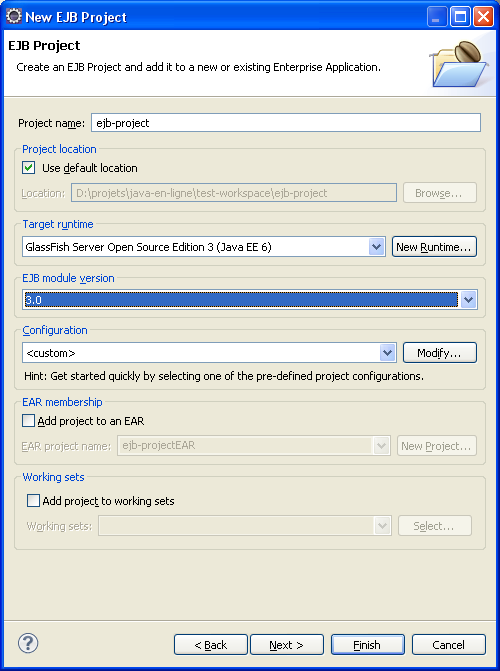
Il ne reste plus qu'à ajouter les deux projets ejb-interface et
jpa-project en dépendance de notre projet ejb-project.
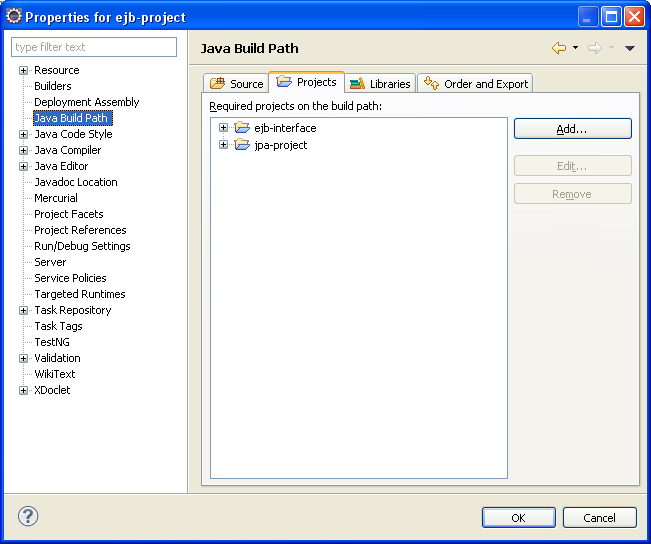
On crée enfin une implémentation de l'interface MarinService, dans ce projet.
Le code de la classe est le suivant.
Exemple 4. Classe MarinServiceImpl
@Stateless(mappedName="MarinService") @Remote public class MarinServiceImpl implements MarinService { @PersistenceContext private EntityManager em ; @Override public long createMarin(String nom, String prenom, int salaire) { Marin marin = new Marin(nom, prenom, salaire) ; em.persist(marin) ; return marin.getId() ; } }
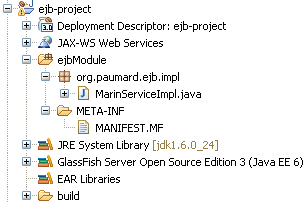
La structure du projet ejb-project est donc la suivante.
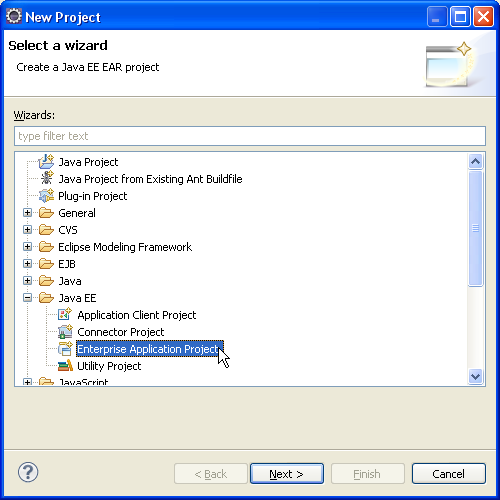
Un projet EAR est un projet qui agrège différents modules, de toute sorte. Un projet EAR peut contenir des EJB, des applications Web, des services Web, des services REST, des services de messagerie, et bien d'autres choses encore. Nous allons nous borner ici à une application très simple et très classique : un module JPA auquel on accède par un EJB façade. Cet EAR va donc être un assemblage de nos trois projets déjà créés.
Un projet EAR est un projet Eclipse d'un type particulier, comme montré sur la figure suivante.
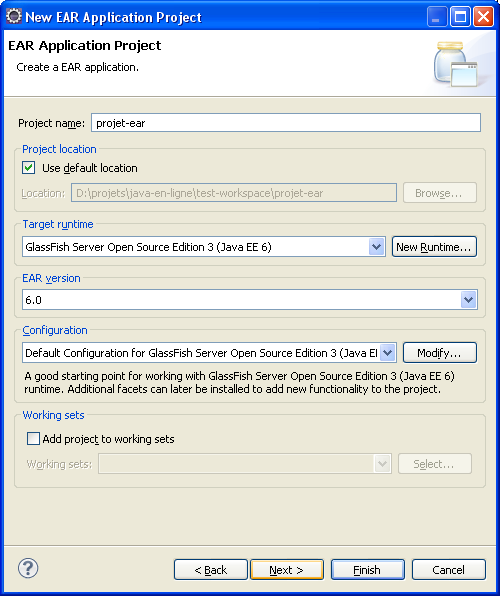
Encore une fois, il faut fixer le type de serveur d'application dans lequel se projet va être déployé.
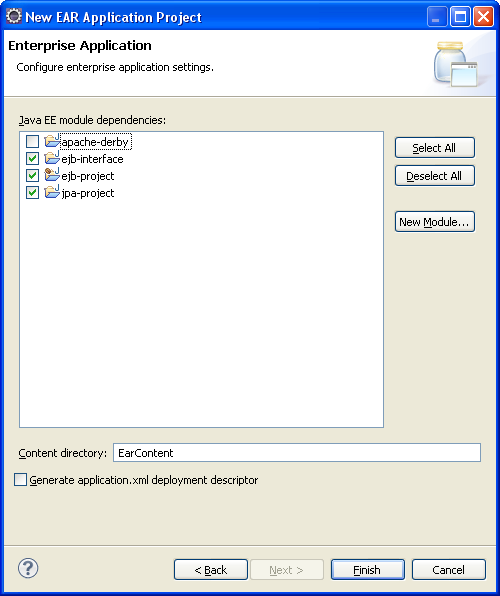
On sélectionne alors les projets qui vont être agrégés par cet EAR.
À l'issue de ces opérations, la structure de notre projet EAR est donc la suivante.
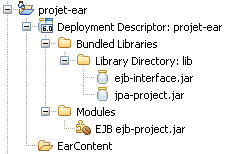
On remarquera que le projet EJB se trouve bien à la racine de cet EAR, et que tous les projets
dont il dépend se trouvent dans le répertoire lib, ce qui est bien conforme à la
spécification.
Notre projet projet-ear est appelé a être déployé dans Glassfish. C'est Glassfish
qui va se charger de lui, et de le rendre disponible aux requêtes des projets clients.
Il existe plusieurs façons de déployer un projet EAR dans un serveur d'application sous Eclipse, la plus simple est probablement de glisser / déposer le projet dans la vue Servers, sur l'élément correspondant au serveur Glassfish, comme sur la figure suivante.

Si le serveur est déjà en marche, le projet va être déployé et disponible en quelques secondes. S'il n'est pas en marche, et qu'il ne démarre pas automatiquement (ce démarrage automatique est le comportement par défaut), alors il faut le lancer à la main.
Une fois déployé, notre serveur Glassfish a la structure suivante.
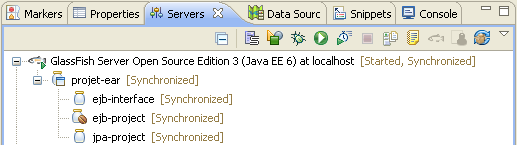
Notre projet EAR, correctement déployé, est prêt à traiter les requêtes extérieures. Pour montrer ce point, nous n'avons plus qu'à écrire un client simple.
Un projet client est un projet Java normal, sans type spécial. Pour se connecter à Glassfish,
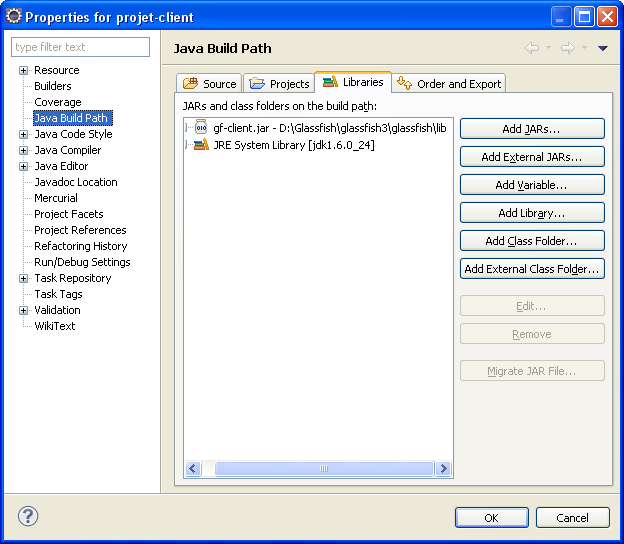
il a juste besoin d'une dépendance vers un JAR de la distribution de Glassfish :
gf-client.jar, qui se trouve dans $GLASSFISH_HOME/glassfish/lib.
Attention toutefois, ce JAR ne contient quasiment rien, mais il référence de très nombreux JAR
du répertoire $GLASSFISH_HOME/glassfish/modules. Si l'on copie juste ce fichier en
le sortant de l'installation de Glassfish, les choses ne se passeront pas bien.
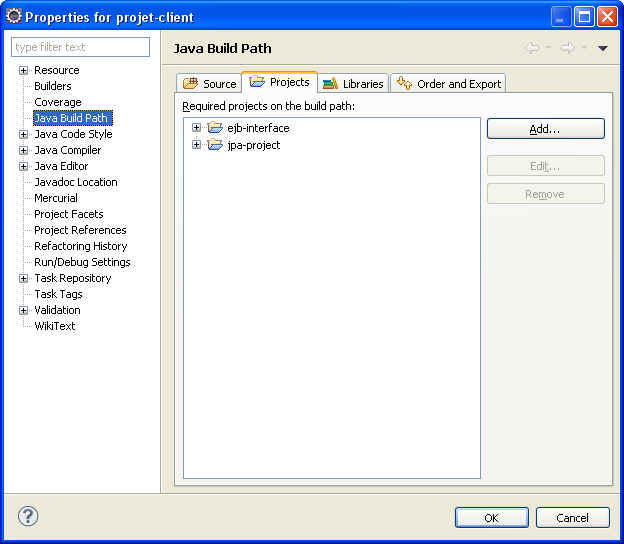
Notre projet client doit de plus référencer les projets contenant les interfaces de nos EJB, et le modèle objet. Il n'a pas besoin de référencer le projet contenant les implémentations de nos EJB.
Voici ses dépendances vers les autres projets.
Et voici ces dépendances vers les JARs de Glassfish.
Il ne nous reste plus qu'à écrire une classe Main afin d'accéder à nos EJB.
Exemple 5. Classe Main cliente
public class Main {
public static void main(String[] args) {
try {
// création du "contexte initial" = de la connexion à l'annuaire du serveur
InitialContext context = new InitialContext();
// requête sur le nom de la ressource que l'on veut, ici notre EJB
MarinService marinService = (MarinService)context.lookup("MarinService") ;
// invocation d'une méthode
long id = marinService.createMarin("Surcouf", "Robert", 5000) ;
System.out.println("Id = " + id) ;
} catch (NamingException e) {
e.printStackTrace();
}
}
}
L'exécution de ce code nous affiche sur la console la clé primaire du marin créé, ce qui est le signe que l'écriture en base s'est bien effectuée.
On n'a pas besoin d'écrire de fichier jndi.properties lorsque l'on procède de la
sorte. Ce fichier est en dépendance du projet, dans les JAR de Glassfish.
Il faut bien comprendre que l'application JPA se trouve physiquement dans l'EAR déployé sous Glassfish. Le cycle de vie de cette application est donc lié à celui de l'EAR. C'est au moment du redémarrage de cet EAR que la base est éventuellement réinitialisée.
Au moment de ce redémarrage, il se peut que des erreurs apparaissent du fait de problèmes SQL,
visibles dans les journaux de l'application (répertoire domaine-tutorial/logs).
Eclipse interprète ces problèmes comme des erreurs, et peut déclarer que l'EAR n'a pas été
déployé correctement. Si c'est le cas, la seule solution est de retirer l'EAR de Glassfish
(option du menu contextuel du projet dans la vue Servers), et de le
déployer à nouveau.
D'une façon générale, le mode drop-and-create ne se comporte pas très bien avec
ce mode de fonctionnement.
José Paumard © 2011, tous droits réservés