Cette stratégie consiste à enregistrer les champs de chaque entité dans une table propre à cette classe. Généralement, les champs d'une entité seront répartis dans plusieurs tables : autant qu'il y a de niveaux dans la hiérarchie d'héritage.
On a donc autant de tables que de classes dans notre modèle, abstraites ou concrètes. Aucune collision de nom ne peut avoir lieu dans cette approche, du fait de l'héritage.
Reprenons notre exemple précédent, en annotant notre classe
On remarque la création d'une table supplémentaire :
Personne avec
@Inheritance(strategy=InheritanceType.JOINED).
Les annotations concernant les colonnes techniques de discrimation d'instances sont toujours nécessaires : la table
Parent continuera à porter des instances de
Maire, même si elle ne les porte que partiellement.
On obtient le schéma suivant.
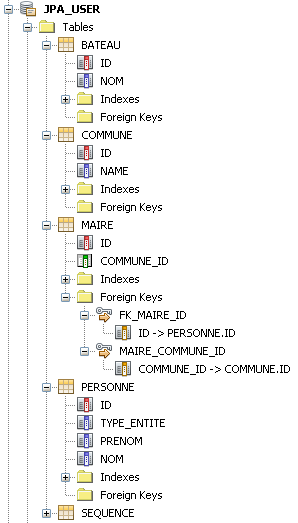
On remarque la création d'une table supplémentaire :
Maire, qui porte la colonne de jointure vers la table
Commune. De fait, cette colonne n'existe plus dans la table
Personne. La table
Personne ne porte pas de colonne
nom ou
prenom. Le nom et le prénom d'un maire sont enregistrés dans la table
Personne.
Enfin on remarque que la table
Maire comporte une clé primaire,
id. Cette clé primaire est aussi une clé étrangère qui référence la clé primaire de la table
Personne. Ces deux tables partagent en fait la même clé primaire, ce qui est logique puisque toutes les lignes de la tables
Maire ont une partie de leurs champs dans la table
Personne.
Cette stratégie peut paraître très satisfaisante car elle respecte la première forme normale. En revanche, pour les hiérarchies importantes, elle pose un gros problème de performances.
Effectivement, et l'on peut s'en rendre compte même sur notre exemple très simple :
-
Toute lecture d'un maire nécessite une jointure avec la table
Personne. -
Tout enregistrement d'un maire en base nécessite deux commandes SQL
INSERT, une dans la tablePersonneet une dans la tableMaire. -
Tout effacement d'un maire nécessite deux commandes SQL
DELETE, une dans la tablePersonneet une dans la tableMaire.
José Paumard © 2018, tous droits réservés
Table des matières
- Introduction
- Un premier exemple
- Mettre un jeu de classes en base
- L'API Collection en base
- Héritage
- Requêtes
- EJB