L'ensemble des opérations montrées ici sont réalisées sous NetBeans 6.9.1. Si l'on veut suivre la construction de ce premier projet pas à pas, c'est cet IDE qu'il faut utiliser.
Commençons tout d'abord par créer une base de données. Nous allons utiliser Derby, intégré à NetBeans. On pourrait tout à fait utiliser une base MySQL ou Postgres, cela reviendrait au même.
La première étape consiste donc à créer une base Derby "JPA_Test" et à s'y connecter. NetBeans demande également un nom d'utilisateur et un mot de passe, qu'il utilise pour créer cette base.
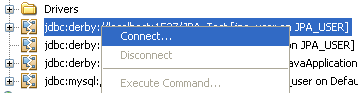
La deuxième étape consiste à se connecter à cette base Derby. Pour cela, il suffit de cliquer sur l'option "Connexion..." du menu.
Notre base Derby est à présent prête à fonctionner.
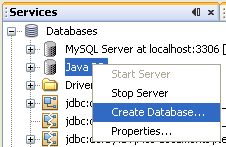
La deuxième étape consiste à se connecter à cette base Derby. Pour cela, il suffit de cliquer sur l'option "Connexion..." du menu.
Notre base Derby est à présent prête à fonctionner.
Le projet NetBeans est un projet Java normal. Effectivement, une classe JPA est une classe Java normale. En particulier elle n'a pas besoin de vivre dans un projet JEE. On crée donc un projet NetBeans de façon classique.
Dans le jargon JPA, une classe "persistante", est aussi appelée une "entité". Ce terme n'est pas à confondre avec la terminologie UML. Une "entité" JPA est une classe Java normale, annotée comme nous allons le voir.
Créons à présent une première entité JPA.
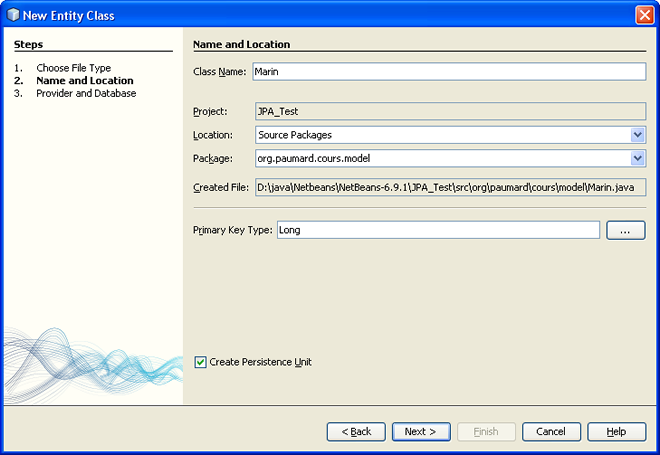
NetBeans nous pose alors une série de questions, qui vont lui permettre de configurer JPA pour nous. La première de ces questions est le type Java utilisé pour coder la clé primaire de notre entité. Cette entité va être associée à des lignes dans une table d'une base de données. Chacune de ces lignes doit posséder une clé primaire. Cette clé primaire sera associée à un champ de notre classe. Le type par défaut
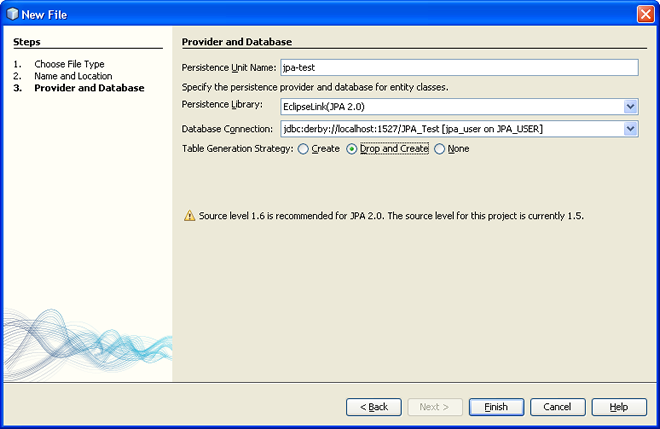
La deuxième étape nous pose quatre questions :
Examinons à présent les différents éléments que NetBeans a créés pour nous.

NetBeans nous pose alors une série de questions, qui vont lui permettre de configurer JPA pour nous. La première de ces questions est le type Java utilisé pour coder la clé primaire de notre entité. Cette entité va être associée à des lignes dans une table d'une base de données. Chacune de ces lignes doit posséder une clé primaire. Cette clé primaire sera associée à un champ de notre classe. Le type par défaut
Long nous convient, n'y touchons pas.
La deuxième étape nous pose quatre questions :
- Le nom de notre persistence unit (unité de persistance). Une unité de persistance est un ensemble de classes persistantes regroupées entre elles, et associées à une même base de données. En général, une application ne manipule qu'une seule unité de persistance à la fois. Chaque unité de persistance doit porter un nom, on choisit ici "jpa-test".
- L'implémentation de JPA utilisée. C'est ici que l'on peut choisir d'utiliser Hibernate, OpenJPA ou EclipseLink. C'est ce dernier choix que l'on fait ici. Choisir une autre implémentation n'a qu'un impact limité dans le contexte de ce cours. Dans une application en production, il est souvent déterminant.
- La connexion à la base de données utilisée par cette unité de persistance. Cette connexion va être utilisée par l'implémentation pour valider le schéma, éventuellement le créer, et surtout faire toutes les lectures / écritures sur la base de données. Ici l'on choisit la base Derby que l'on vient de créer.
-
Enfin, le dernier paramètre à fixer décide de la stratégie de génération du schéma de tables que notre unité de persistance va utiliser. Cette stratégie s'applique au lancement de notre application. Trois options sont offertes. L'option
createpermet de créer les tables si elles n'existent pas déjà. L'optiondrop and createefface le contenu du schéma systématiquement à chaque lancement. Cette option n'est utilisable qu'en phase de développement et de test, et uniquement si notre modèle ne comporte pas trop d'entités, ni trop de tables. Enfin, l'optionnonene fait rien. On choisit dans cet exemple l'optiondrop and create.
Examinons à présent les différents éléments que NetBeans a créés pour nous.
Un projet persistant est composé de trois éléments :
Il manque toutefois un élément à ce projet, que NetBeans ne nous donne pas automatiquement : le pilote JDBC de Derby. Pour que notre configuration soit complète, il faut ajouter le JAR de ce pilote aux librairies de notre projet.
-
Un jeu de classes persistantes, ici nous n'en avons qu'une :
Marin. -
Un descripteur d'unité de persistances : il s'agit d'un fichier
persistence.xml, rangé dans le répertoireMETA-INFdu projet. -
Les JAR contenant les annotations JPA, et l'implémentation choisie. Ici il s'agit des JARs
eclipselink-javax.persistence-2.0.jareteclipselink-2.0.2.jarrespectivement.
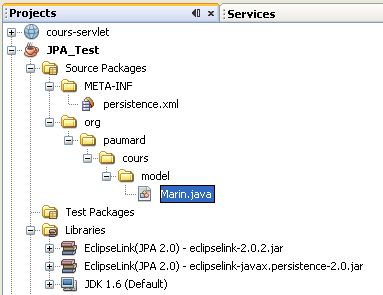
Il manque toutefois un élément à ce projet, que NetBeans ne nous donne pas automatiquement : le pilote JDBC de Derby. Pour que notre configuration soit complète, il faut ajouter le JAR de ce pilote aux librairies de notre projet.
Notre première classe persistante est la classe
On remarque tout d'abord la présence de trois éléments nouveaux :
Marin. Examinons le code que NetBeans a généré pour nous.
Exemple 1. Une première classe persistante
@Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; public Long getId() { return id; } public void setId(Long id) { this.id = id; } // suivent les méthode toString(), equals() et hashCode() }
On remarque tout d'abord la présence de trois éléments nouveaux :
@Entity,
@Id et
@GeneratedValue. Ces éléments, qui commencent par le caractère
@ sont des annotations. D'une façon générale, une annotation est une information que l'on donne à la machine Java sur le fonctionnement de l'élément annoté.
Par exemple,
@Entity placé sur un nom de classe indique à la machine Java que cette classe est une classe persistante, et qu'elle doit être associée à une ou plusieurs tables de la base de données.
L'annotation
@Id indique que ce champ est la clé primaire pour la classe
Marin. Comme c'est la base de données qui génère elle-même les valeurs des différentes clés primaires, nous lui indiquons juste une stratégie de génération, par l'annotation supplémentaire
@GeneratedValue(strategy = GenerationType.AUTO).
Toute application JPA doit comporter au moins un fichier
Tout d'abord, l'élément racine de ce fichier est
persistence.xml. C'est dans ce fichier que se trouvent tous les éléments qui permettent de créer les
unités de persistance
, dont nous allons nous servir pour utiliser notre application.
Examinons le contenu de ce fichier.
Exemple 2. Un premier
persistence.xml
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="jpa-test" transaction-type="RESOURCE_LOCAL"> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <class>org.paumard.cours.model.Marin</class> <properties> <property name="javax.persistence.jdbc.url" value="jdbc:derby::1527/JPA_Test"/> <property name="javax.persistence.jdbc.password" value="jpa_passwd"/> <property name="javax.persistence.jdbc.driver" value="org.apache.derby.jdbc.ClientDriver"/> <property name="javax.persistence.jdbc.user" value="jpa_user"/> <property name="eclipselink.ddl-generation" value="drop-and-create-tables"/> </properties> </persistence-unit> </persistence>
Tout d'abord, l'élément racine de ce fichier est
persistence. Cet élément peut comporter autant de sous-éléments
persistence-unit que l'on veut. Cela dit, généralement on n'en trouve qu'une seule.
Chaque élément
persistence-unit définit une unité de persistance. Il doit porter un nom (attribut
name), et un attribut
transaction-type, qui peut prendre deux valeurs :
RESOURCE_LOCAL comme ici, ou
JTA.
Cet élément
persistence-unit doit comporter un unique sous-élément
provider. C'est cet élément qui définit l'implémentation JPA utilisée. Ici, il s'agit d'EclipseLink.
Suit la liste des classes persistantes. Cet élément est en fait facultatif.
Enfin, se trouve une liste de propriétés, qui vont permettre à l'unité de persistance de fonctionner. Les premières propriétés de notre exemple sont standard, et permettent à l'unité de persistance d'ouvrir une connexion JDBC vers la base que nous avons définie. La propriété
eclipselink.ddl-generation est propre à EclipseLink, et définit le comportement lors du lancement de l'application.
José Paumard © 2018, tous droits réservés
Table des matières
- Introduction
- Un premier exemple
- Mettre un jeu de classes en base
- L'API Collection en base
- Héritage
- Requêtes
- EJB