Le pattern
session facade
est celui qui définit la façon dont on accède à un modèle d'objets persistants dans un environnement JEE5.
D'une façon générale, tous les patterns de programmation qui portent le nom
facade
sont écrits dans la même idée : masquer la complexité technique d'une suite d'opérations, et les rendre accessibles en un appel de méthode unique. Une façade agit donc comme une enveloppe, et expose des fonctionnalités simples clairement définies.
Une EJB
session facade
est donc un EJB
stateless
, qui connaît notre modèle objet, connaît notre unité de persistance, et expose les opérations CRUD de manipulation de nos données, en plus d'opérations plus complexes, prédéfinies.
Enrichissons notre exemple simple du chapitre précédent, afin d'illustrer ce concept. Notre modèle sera particulièrement simple, il ne comportera qu'une unique classe :
Donnons ici le code de notre classe
Notons que le projet cours-ejb-model doit avoir une dépendance vers EclipseLink, puisque la classe
Marin. Afin de porter cette classe, on crée un nouveau projet Netbeans, cours-ejb-model. Ce projet est un projet Java classique, il ne définit pas d'unité de persistence, nous verrons pourquoi dans la suite.
Voici sa structure.
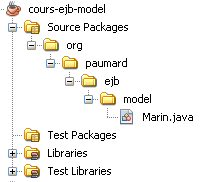
Donnons ici le code de notre classe
Marin. Il s'agit d'une entité JPA classique.
Exemple 60. Classe
Marin du modèle
package org.paumard.ejb.model ; @Entity public class Marin implements Serializable { private static final long serialVersionUID = 1L; @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; private String nom ; // reste de la classe }
Notons que le projet cours-ejb-model doit avoir une dépendance vers EclipseLink, puisque la classe
Marin porte des annotations JPA.
Nous n'avons pas encore décrit la structure d'un fichier EAR. Disons pour le moment qu'il s'agit d'une archive, au même sens qu'un fichier JAR ou WAR, qui possède une structure interne spéciale. Notamment, le standard EAR exige que seuls les JAR contenant des EJB peuvent être rangés à la racine de cette archive, tous les autres JAR doivent être rangés dans un sous-répertoire
lib de ce fichier EAR. C'est donc dans ce répertoire que le JAR de ce projet devra être rangé au final.
Où doit-on placer notre fichier
On ne définit pas une unité de persistance dans un contexte JEE de la même façon que dans un contexte JSE, comme nous l'avons fait au chapitre précédent. Comme nous l'avons déjà vu, un serveur d'application quel qu'il soit, sait se connecter à des bases de données, et expose ses connexions dans son annuaire au travers d'objets de type
persistence.xml, celui dans lequel nous devons définir notre unité de persistance ? On a en fait plusieurs choix. Soit l'ensemble des classes de notre modèle est rangé dans le même JAR, et dans ce cas, le plus simple est de ranger ce fichier dans le répertoire
META-INF de JAR. Soit les entités JPA de notre modèle sont réparties dans plusieurs JAR (ce qui est parfaitement légal), auquel cas, le plus logique est de le ranger dans le répertoire
META-INF de son propre JAR, de façon à ne pas privilégier un JAR du modèle plutôt qu'un autre. C'est cette façon de faire que nous choisissons ici, aussi pour traiter par l'exemple un cas de configuration non trivial.
Créons donc un projet cours-ejb-persistence, qui ne porte que ce fichier
persistence.xml. Voici sa structure.
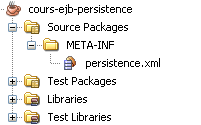
On ne définit pas une unité de persistance dans un contexte JEE de la même façon que dans un contexte JSE, comme nous l'avons fait au chapitre précédent. Comme nous l'avons déjà vu, un serveur d'application quel qu'il soit, sait se connecter à des bases de données, et expose ses connexions dans son annuaire au travers d'objets de type
DataSource. Lorsqu'un module d'une application entreprise a besoin d'accéder à une base de données, en aucun cas elle n'ouvre la connexion à cette base elle-même : elle utilise plutôt l'une de ces sources de données, en l'appelant par son nom. C'est ce que fait notre unité de persistance, qui, plutôt que de définir les coordonnées d'une connexion JDBC, comme nous l'avons fait au chapitre précédent, va référencer une source de données existante, définie au niveau de notre serveur d'applications.
On peut définir une telle source de données en utilisant Netbeans. Pour cela, il faut aller dans le menu New... > Other... du nœud Server Resources de notre projet cours-ear.
On choisit alors l'option JDBC Resources, dans l'onglet Glassfish, comme sur la figure suivante.
La fenêtre suivante nous demande deux choses.
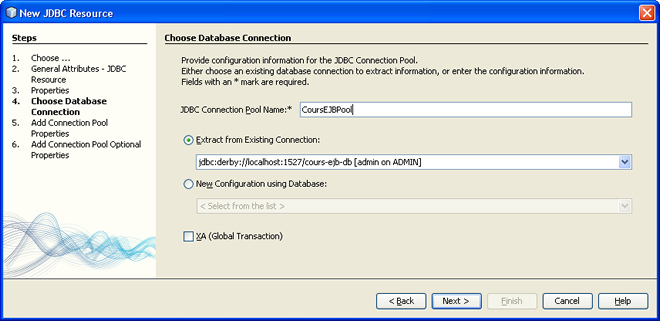
La fenêtre suivante nous propose d'entrer des propriétés supplémentaires, et dans cet exemple nous n'en avons pas. Ensuite nous passons à la définition de notre réserve de connexions. Cette réserve est une ressource enregistrée dans l'annuaire, elle doit donc porter un nom. On doit également lui définir une connexion à une base de données. Pour cela, Netbeans nous propose les connexions qu'il connait.
Les deux dernières étapes permettent de revoir les choix, et éventuellement de les modifier. À l'issue de ce processus, un fichier
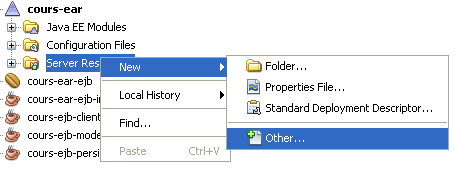
On choisit alors l'option JDBC Resources, dans l'onglet Glassfish, comme sur la figure suivante.
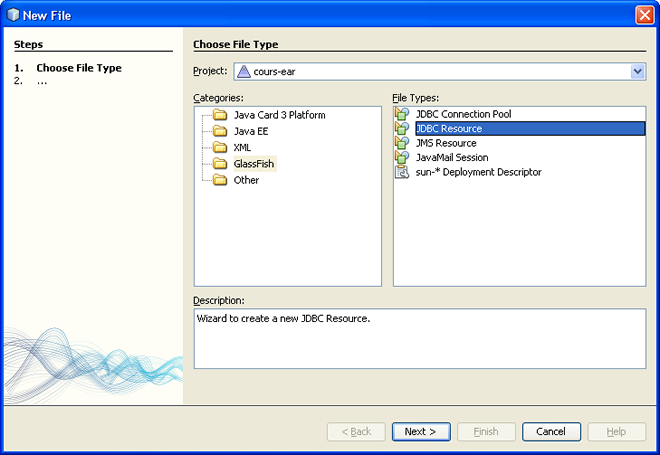
La fenêtre suivante nous demande deux choses.
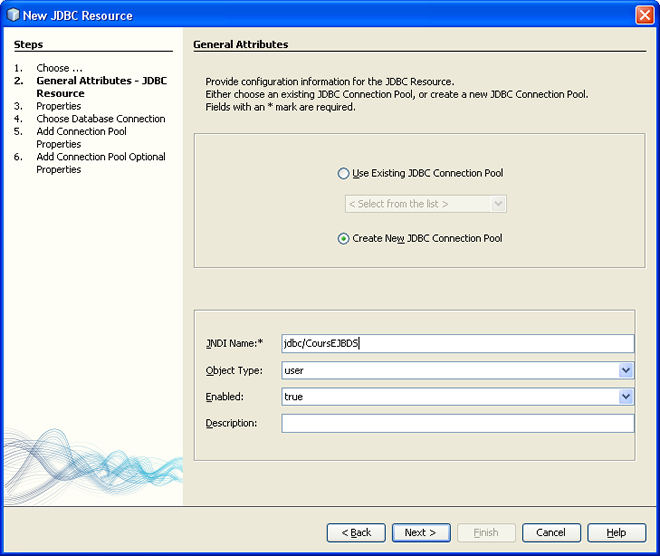
- La réserve de connexions JDBC sur laquelle cette source de données va s'appuyer. Effectivement, plutôt que de ne fonctionner qu'avec une connexion unique, les sources de données s'appuient sur des réserves de connexions, ouvertes à la demande, et fermées automatiquement si elles ne sont pas utilisées.
-
Le nom de cette source de données dans l'annuaire (JNDI) du serveur d'applications. On choisira
jdbc/CoursEJBDScomme nom, c'est par ce nom que notre unité de persistance pourra se connecter à la base.
La fenêtre suivante nous propose d'entrer des propriétés supplémentaires, et dans cet exemple nous n'en avons pas. Ensuite nous passons à la définition de notre réserve de connexions. Cette réserve est une ressource enregistrée dans l'annuaire, elle doit donc porter un nom. On doit également lui définir une connexion à une base de données. Pour cela, Netbeans nous propose les connexions qu'il connait.
Les deux dernières étapes permettent de revoir les choix, et éventuellement de les modifier. À l'issue de ce processus, un fichier
sun-ressources.xml est créé dans notre projet cours-ear, dans le nœud Server resources.
Malheureusement, vue la structure de modules que l'on a choisie pour déployer notre projet, les wizards automatiques de Netbeans ne vont pas nous permettre de générer le fichier
Deux éléments ont changé dans ce fichier, par rapport à celui que l'on avait écrit dans le chapitre précédent.
Le reste du fichier ne change pas, mis à part que l'on n'a plus besoin des propriétés que JDBC utilisait pour se connecter à la base.
persistence.xml. Voici donc son contenu.
Exemple 61. Fichier
persistence.xml
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="cours-ear-pu" transaction-type="JTA"> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <jta-data-source>jdbc/CoursEJBDS</jta-data-source> <class>org.paumard.ejb.model.Marin</class> <properties> <property name="eclipselink.ddl-generation" value="drop-and-create-tables"/> </properties> </persistence-unit> </persistence>
Deux éléments ont changé dans ce fichier, par rapport à celui que l'on avait écrit dans le chapitre précédent.
-
Tout d'abord l'attribut
transaction-typede l'élémentpersitence-unita la valeurJTA. Cela signifie que les transactions de cette unité de persitance seront gérées par le serveur d'application, et non plus à la main. Nous verrons les conséquences de ce point dans la suite. -
On voit apparaître un élément
jta-data-source. Cet élément porte le nom de la source de données que l'on vient de créer. Notre unité de persistance se connectera à la base en utilisant cette source de données.
Nous avons donc maintenant cinq modules dans notre projet.
Notre application entreprise est maintenant prête à être assemblée. La définition de cet assemblage se fait dans les propriétés de ce module, dans l'onglet Packaging.
On notera que tous les JARS en dépendance sont rangés dans le répertoire

- cours-ear est notre projet maître, c'est lui qui sera déployé dans Netbeans. Le module cours-ear-ejb est un de ses sous-modules, il le possède donc automatiquement en dépendance. Il définit en plus des dépendances vers les trois autres modules : cours-ear-ejb-interfaces, cours-ejb-model et cours-ejb-persistence. Il dépend également d'EclipseLink.
- cours-ear-ejb porte l'implémentation de nos EJB. Ce module dépend des modules cours-ejb-model et cours-ear-ejb-interfaces. Pour le moment l'implémentation de nos EJB ne dépend pas effectivement de notre modèle, mais ce point va changer.
- cours-ear-ejb-interfaces porte les interfaces implémentées par nos EJB. Ce module dépend du module cours-ejb-model, et d'EclipseLink.
- cours-ejb-model porte nos classes persistantes, et ne dépend que d'EclipseLink.
-
cours-ejb-persistence ne porte que notre unité de persistance, déclarée dans le fichier
persistence.xml. Comme ce module ne porte pas de code, il ne dépend de rien. - Le module cours-ejb-client est particulier. Il ne fait pas partie de notre application d'entreprise, mais c'est lui qui sera utilisé pour y accéder.
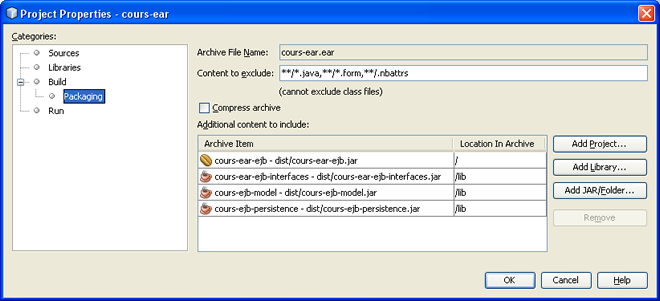
On notera que tous les JARS en dépendance sont rangés dans le répertoire
lib de cet EAR.
L'assemblage final de cet EAR est lancé en sélectionnant l'option Clean and Build du menu contextuel du nœud du projet cours-ear. Lorsque l'on lance cette opération, Netbeans lance un certain nombre de scripts, finit par annoncer que l'opération s'est correctemet déroulée. Le résultat est un fichier
.ear, rangé dans le répertoire
dist de notre projet. La structure de ce fichier doit exactement suivre celle de la répartition de nos modules dans l'application.
Le déploiement dans Glassfish se fait en invoquant l'option Deploy du même menu. L'EAR est alors pris en compte par Glassfish, qui va déployer les EJB, initialiser la source de données, charger l'unité de persistance, et créer la structure de base de données en conséquences.
De la même façon, cette opération doit se terminer par l'apparition d'un message de victoire dans la console.
En cas de problème de déploiement, il peut être assez difficile de diagnostiquer ce qui ne va pas. Un point de départ peut être le contenu du répertoire
cours-ear/cours-ear/dist. Ce répertoire contient deux choses. Tout d'abord le fichier EAR déployé par Glassfish. Ensuite l'ouverture de ce fichier par Glassfish, rangée dans le sous-répertoire
gfdeploy. Examiner le contenu de ces deux éléments peut permettre de détecter des problèmes d'assemblage, et de les corriger.
José Paumard © 2018, tous droits réservés
Table des matières
- Introduction
- Un premier exemple
- Mettre un jeu de classes en base
- L'API Collection en base
- Héritage
- Requêtes
- EJB