Dans de nombreux cas, mettre des objets en relation est très coûteux et inutile. Coûteux pour deux raisons :
Elle peut être inutile, notamment dans le cas où l'objet en relation partage complètement le cycle de vie de l'objet maître. Dans ce cas, créer une relation
- Surcharge en lecture et écriture : la lecture entraîne une jointure, ou une requête supplémentaire, l'insertion une requête supplémentaire.
- Les objets en relations sont stockées dans une table à part, qui peut contenir des quantités très importantes d'objets.
@OneToOne est un luxe.
JPA propose pour cela une fonctionnalité, qui permet d'inclure les champs de l'objet en relation avec ceux de l'objet maître. Cette technique résout tous les problèmes.
On déclare une classe d'objets inclus en annotant simplement la classe de ces objets avec
On remarque tout d'abord que cette classe n'est pas annotée avec
@Embeddable plutôt qu'
@Entity. Les contraintes sur ces classes sont les mêmes : elles doivent être sérializables, et comporter un constructeur vide, par défaut ou explicite.
Une entité incluse n'a pas besoin de déclarer de clé primaire : elle n'a pas de table en propre, et partagera donc la même clé primaire que les objets qui la déclarent en relation.
Voyons un exemple d'objet inclus.
Exemple 17. Déclaration d'objets inclus
@Embeddable public class Adresse implements Serializable { @Column(length=40) private String rue ; @ManyToOne private Commune commune ; // reste de la classe }
On remarque tout d'abord que cette classe n'est pas annotée avec
@Entity, il ne s'agit donc pas d'une entité JPA. Elle est annotée avec
@Embeddable, et ne pourra être utilisée que dans des relations annotées avec
@Embedded.
Cette classe va nous permettre d'ajouter une adresse à nos marins. On remarque que l'objet inclus est lui-même en relation avec les communes, ce qui est autorisé.
Ajoutons une adresse à nos marins sur l'exemple suivant.
Plutôt que d'annoter la relation
On constate que le schéma généré comporte bien la colonne
Exemple 18. Utilisation d'objets inclus
@Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String name ; @Embedded private Adresse adresse ; // reste de la classe }
Plutôt que d'annoter la relation
adresse avec
@OneToOne, comme on l'aurait fait pour une relation classique, nous l'avons annotée avec
@Embedded, ce qui signifie que les champs de notre adresse seront créés directement dans la table
Marin. Un objet référencé dans une relation annotée par
@Embedded doit nécessairement être annoté par
@Embeddable.
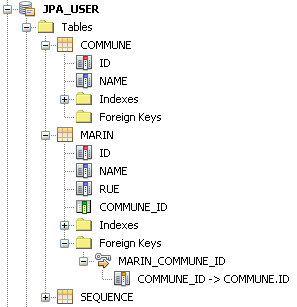
On constate que le schéma généré comporte bien la colonne
rue et la colonne de jointure vers la table
Commune.
Du point de vue du graphe d'objets rien n'empêche un objet inclus d'être nul : après tout, ce n'est qu'une relation comme les autres, qui peut très bien ne pointer vers rien. Du point de vue de la base de données, le problème est différent : rien ne différencie un marin dont on ne connaît pas l'adresse, d'un marin qui en a une.
Si l'on tente d'écrire en base un marin qui n'a pas d'adresse, on risque d'obtenir une exception, dans la mesure où les objets inclus nuls ne sont pas autorisés en JPA.
Si l'on lit un marin en base qui n'a pas d'adresse, on obtiendra un objet Java
Dans ces deux cas il faut modifier le
getter
du champ inclus de façon à ce qu'il retourne
JPA nous crée alors le schéma suivant, nous allons pouvoir enregistrer des valeurs nulles dans notre modèle d'objets Java.
marin, qui possède une adresse dont tous les champs sont vides.
On peut mettre en place plusieurs solutions pour régler ce problème :
-
Créer un objet
adresseparticulier, dont les champs indiquent que cet objet correspond à un objet nul. Cette approche n'est valide que dans certains cas, dans d'autres, une telle configuration de champs n'existe pas. - Ajouter à l'objet inclus une colonne technique, booléenne, qui indique que cet objet est en fait nul. Cette approche fonctionne dans tous les cas.
null quand le champ inclus est en fait nul. Voyons ceci sur un exemple.
On notera deux choses sur cet exemple :
-
Le booléen
isNullde la classeAdresseest positionné àtruepar défaut. Donc, toute relation vers une adresse initialisée avec une adresse vide génèrera un retournullsur appel du getter de cette relation. -
Dans la classe
Marin, le champadresseest initialisé sur une valeur particulière :Adresse.ADRESSE_NULL, de façon à ne jamais être nul. Cela permet d'éviter les éventuelles erreurs si cette relation n'a pas été initialisée. Notons que l'objetAdresse.ADRESSE_NULLgénère bien un retour nul du getter associé.
Exemple 19. Champ inclus nul
// // Entité Adresse // @Embeddable public class Adresse implements Serializable { private boolean isNull = true ; private String rue ; @ManyToOne private Commune commune ; // objet adresse utilisé pour l'initialisation // le champ isNull de cet objet est true public static ADRESSE_NULL = new Adresse() ; // méthode appelée par les getters public static Adresse getAdresse(Adresse adresse) { if (adresse == null || adresse.isNull) { return null ; } else { return adresse ; } } // reste de la classe } // // Entité Marin // @Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String name ; // le champ est initialisé non nul, afin d'éviter // les erreurs à l'écriture @Embedded private Adresse adresse = Adresse.ADRESSE_NULL ; // Getter pour l'adresse public Adresse getAdresse() { return Adresse.getAdresse(this.adresse) ; } // reste de la classe }
JPA nous crée alors le schéma suivant, nous allons pouvoir enregistrer des valeurs nulles dans notre modèle d'objets Java.
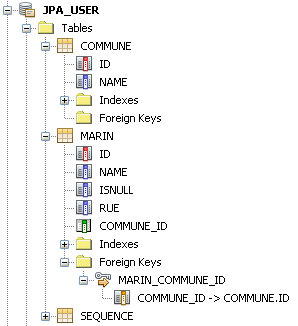
Il nous reste un dernier problème à traiter : que se passe-t-il si nous devons enregistrer plusieurs instances d'une même classe d'objets inclus dans une entité ?
La réponse dépend de l'implémentation, et dans chaque implémentation, peut dépendre de la version que l'on utilise. Si l'implémentation est maligne, elle va se rendre compte qu'il y a une collision de noms, et le gérer en ajoutant des numéros à ces noms. C'est ce que fait Hibernate. Si elle est moins maligne, elle ne va pas voir la collision de nom, et ne pas créer le bon nombre de colonnes. C'est ce que fait EclipseLink 2.0.2.
Comme d'habitude dans pareil cas, il faut appliquer le vieux proverbe : on n'est jamais aussi bien servi que par soi-même, et utiliser la possibilité que JPA nous donne de surcharger le nommage des colonnes des objets inclus.
Du point de vue de JPA, la classe
Comme la classe
Techniquement, l'annotation
Exemple 20. Renommage des colonnes des objets inclus
@Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String name ; @Embedded @AttributeOverrides({ @AttributeOverride( name="isNull", column=@Column(name="adr_courante_isnull")), @AttributeOverride( name="rue", column=@Column(name="adr_courante_rue")) }) @AssociationOverrides({ @AssociationOverride( name="commune", joinColumns=@JoinColumn(name="adr_courante_commune_id")) }) private Adresse adresseCourante ; @Embedded @AttributeOverrides({ @AttributeOverride( name="isNull", column=@Column(name="adr_naissance_courante_isnull")), @AttributeOverride( name="rue", column=@Column(name="adr_naissance_courante_rue")) }) @AssociationOverrides({ @AssociationOverride( name="commune", joinColumns=@JoinColumn(name="adr_naissance_commune_id")) }) private Adresse adresseDeNaissance ; // reste de la classe }
Du point de vue de JPA, la classe
Adresse porte deux types de champs : des types de base et des relations. Les types de base sont stockés dans des colonnes, et les relations dans des colonnes de jointure, qui peuvent être rangées dans la même table qu'une autre entité, ou dans une table propre (table de jointure).
On renomme une colonne par l'annotation
@AttributOverride. Cette annotation prend deux attributs :
-
name, de typeString: désigne le nom du champ dans la classe ; -
column, de type@Column: définit la colonne dans laquelle ce champ sera enregistré. Le type@Columndéfinit lui-même plusieurs attributs, dontnameque nous utilisons ici.
Adresse porte deux champs :
isNull et
rue, nous devons utiliser deux annotations
@AttributeOverride. Ces deux annotations sont regroupées dans une annotation
@AttributeOverrides (notons le "s" à la fin), placée sur le champ inclus.
Reste la relation que
Adresse porte, vers
Commune. Cette relation est ici enregistrée dans une colonne de jointure, clé étrangère qui référence la clé primaire de la table
Commune.
On redéfinit le nom de cette colonne en utilisant une annotation
@AssociationOverride, qui fonctionne de la même façon que
@AttributeOverride. Elle définit trois attributs :
-
name, de typeString: désigne le nom du champ dans la classe. Cet attribut est le même que dans@AttributeOverride. -
joinColumns, de type tableau de@JoinColumn. Effectivement, JPA supporte les clés primaires composites (ce point n'est pas traité ici), et dans ce cas une jointure peut être enregistrée dans plusieurs colonnes. Ici ce tableau ne porte qu'une unique valeur, de type@JoinColumn. -
joinTable: comme on l'a vu, la jointure peut être enregistrée dans une table de jointure. Dans ce cas, cet attribut nous donne le nom de cette table.
@JoinColumn fonctionne comme l'annotation
@Column, et définit des attributs équivalents.
On obtient alors le schéma suivant.
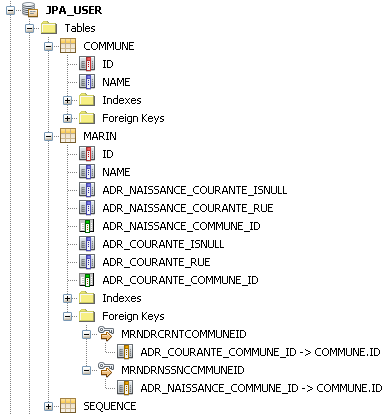
Il est possible pour une entité JPA de posséder une collection d'objets
@Embeddable. Une telle collection doit être annotée
@ElementCollection, comme une collection dont les éléments sont des types de base. Les objets inclus seront alors enregistrés dans une table à part, de la même manière que les types de base.
José Paumard © 2018, tous droits réservés
Table des matières
- Introduction
- Un premier exemple
- Mettre un jeu de classes en base
- L'API Collection en base
- Héritage
- Requêtes
- EJB