-
relation 1:1 : annotée par
@OneToOne; -
relation n:1 : annotée par
@ManyToOne; -
relation 1:p : annotée par
@OneToMany; -
relation n:p : annotée par
@ManyToMany.
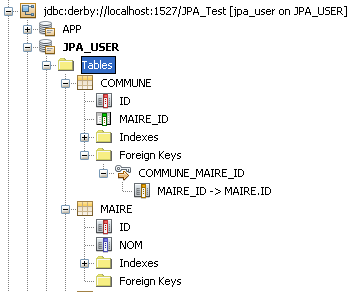
Commune et des
Maire. Chaque commune possède un
maire, et un
maire ne peut être
maire que d'une seule
commune. Nous avons donc bien une relation 1:1 entre les communes et leurs maires. Supposons que dans notre exemple, ce sont les communes qui tiennent la relation entre les communes et les maires.
Exemple 7. Relation 1:1 unidirectionnelle
// // Entité Maire // @Entity public class Maire implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String nom ; // suite de la classe } // // Entité Commune // @Entity public class Commune implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String nom ; @OneToOne private Maire maire ; // suite de la classe }
La relation que nous venons d'écrire est unidirectionnelle, en ce sens que l'on peut connaître le maire d'une commune, mais rien dans la classe
Maire ne nous permet de connaître la commune dont il est maire. Ce cas est le plus simple à traiter : il suffit d'annoter la relation
maire avec
@OneToOne.
En base, les choses se passent assez simplement : une colonne
maire_id va être créée dans la table
Commune. Cette colonne sera une clé étrangère référençant la colonne
id de la table
Maire. On peut imposer le nom de cette colonne en ajoutant l'annotation
@JoinColumn(name="...") sur la relation
maire.
L'annotation
@OneToOne permet de préciser deux comportements importants dans la gestion des relations en JPA : le comportement
cascade
et le comportement
fetch
, que nous verrons à la fin de cette partie.
@OneToOne et un attribut
mappedBy, qui doit référencer le champ qui porte la relation côté maître. Créons par exemple un champ retour dans notre classe
Maire. L'attribut
mappedBy est défini sur l'entité esclave de la relation.
Exemple 8. Relation 1:1 bidirectionnelle
// // Entité Maire // @Entity public class Maire implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column(length=40) private String nom ; @OneToOne(mappedBy="maire") // référence la relation dans la classe Commune private Commune commune ; // suite de la classe }
Définir une relation bidirectionnelle en JPA permet de créer le jeu de clés étrangères qui permet de garantir l'intégrité référentielle de la base de données. Il appartient au code Java de fixer la valeur du champ retour afin de garantir la cohérence du modèle objet. Une relation bidirectionnelle ne se comporte pas comme deux relations unidirectionnelles. Effectivement, une relation unidirectionnelle est caractérisée par une colonne de jointure sur la table maître, et une clé étrangère de cette colonne vers la clé primaire de l'entité en relation. Deux relations unidirectionnelles créeront donc deux colonnes de jointure, dans chacune des deux tables en relation. Une relation bidirectionnelle ne crée pas cette deuxième colonne de la table de jointure, de la table esclave vers la table maître. Lorsque l'on veut lire la relation retour, à partir de l'esclave, une requête est lancée sur la base, en utilisant le caractère bidirectionnel de la relation.
Collection dans la classe maître. La classe esclave ne porte pas de relation retour. Cette relation peut être spécifiée soit par l'annotation
@OneToMany ou
@ManyToMany.
Elle peut être unidirectionnelle ou bidirectionnelle. Dans ce second cas, le côté maître est obligatoirement le côté qui tient la relation monovaluée.
Exemple 9. Relation 1:p unidirectionnelle
// // Entité Marin // @Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; // reste de la classe } // // Entité Bateau // @Entity public class Bateau implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @OneToMany private Collection<Marin> marins ; // reste de la classe }
Voici le schéma créé par EclipseLink.
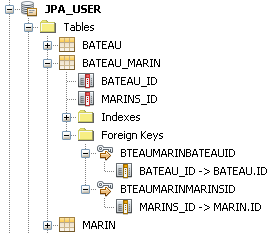
On peut ici se poser une question : pourquoi la spécification JPA prévoit-elle la création d'une table de jointure alors que la relation est de type 1:p ? La réponse est simple : parce qu'aucune information n'existe sur le champ retour, et que JPA n'a donc aucune information sur la colonne de jointure à utiliser dans la table destination. Dans le cas 1:p bidirectionnel, nous verrons que JPA ne crée pas cette table de jointure. Nous avons écrit que l'on pouvait utiliser l'annotation
@OneToMany ou
@ManyToMany pour spécifier cette relation. Cela dit, il faut noter que les deux annotations ne sont pas équivalente. Dans le premier cas, JPA ajoute une contrainte d'unicité sur la clé étrangère de la table de jointure vers la table
Marin. C'est bien ce que nous voulons ici : un même marin ne peut pas appartenir à plusieurs équipages à la fois. Il faut toutefois bien avoir présent à l'esprit cette contrainte : une relation de type 1:p est parfois une relation
@ManyToMany.
mappedBy sur la relation.
JPA nous pose une contrainte ici : l'attribut
mappedBy est défini pour l'annotation
@OneToMany, mais pas pour l'annotation
@ManyToOne. Or, comme nous l'avons vu dans le cas de l'annotation
@OneToOne,
mappedBy doit être précisé sur le côté esclave d'une relation. Dans le cas d'une relation 1:p bidirectionnelle, JPA ne nous laisse donc pas le choix de l'entité maître et de l'entité esclave.
Exemple 10. Relation 1:p bidirectionnelle
// // Entité Marin // @Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @ManyToOne private Bateau bateau ; // reste de la classe } // // Entité Bateau // @Entity public class Bateau implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @OneToMany(mappedBy="bateau") private Collection<Marin> marins ; // reste de la classe }
Examinons le schéma de base généré par JPA.
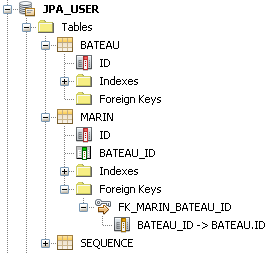
JPA a créé une colonne de jointure dans la table de l'entité cible (ici
Marin), de façon à établir la jointure. Il a de plus créé une clé étrangère vers la clé primaire de la table
Bateau.
Comme on le voit, JPA n'a plus besoin dans ce cas d'une table de jointure pour coder cette relation. On retombe donc dans le cas nominal d'une relation 1:p avec colonne de jointure dans la table cible de la relation.
Exemple 11. Relation p:1 unidirectionnelle
// // Entité Marin // @Entity public class Marin implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @ManyToOne private Bateau bateau ; // reste de la classe } // // Entité Bateau // @Entity public class Bateau implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; // reste de la classe }
Cette fois-ci notre classe
Marin possède un champ
bateau, sans que cette classe n'ait accès à la liste de son équipage.
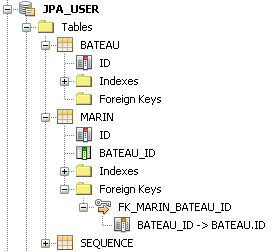
Comme on le voit, JPA a créé une colonne de jointure dans la table
Marin, et une clé primaire qui référence la clé primaire de la table
Bateau.
Exemple 12. Relation n:p unidirectionnelle
// // Entité Musicien // @Entity public class Musicien implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @ManyToMany private Collection<Instrument> instruments ; // reste de la classe } // // Entité Instrument // @Entity public class Instrument implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; // reste de la classe }
JPA génère le schéma suivant pour ce jeu de classes. Une table de jointure est créé entre les deux tables qui portent les entités. Cette table référence les deux clés primaires des deux entités au travers de clés étrangères. Le schéma généré est donc ici tout à fait classique.
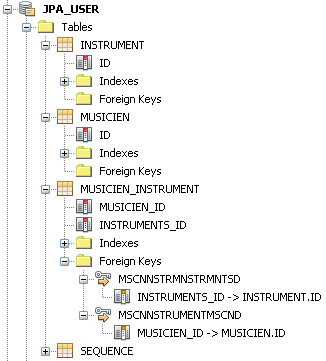
@ManyToMany vers l'entité maître. Cette relation doit comporter un attribut
mappedBy, qui indique le nom de la relation correspondante dans l'entité maître.
Exemple 13. Relation n:p bidirectionnelle
// // Entité Musicien // @Entity public class Musicien implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @ManyToMany private Collection<Instrument> instruments ; // reste de la classe } // // Entité Instrument // @Entity public class Instrument implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @ManyToMany(mappedBy="instruments") private Collection<Musicien> musiciens ; // reste de la classe }
Dans ce deuxième cas, la structure de tables générée est la même. Notons encore une fois que c'est la présence de l'attribut
mappedBy qui crée le caractère bidirectionnel de la relation. Si l'on ne le met pas, alors JPA créera une seconde table de jointure.
DETACH,
MERGE,
PERSIST,
REMOVE,
REFRESH.
Le comportement
cascade
consiste à spécifier ce qui se passe pour une entité en relation d'une entité père (que cette relation soit monovaluée ou multivaluée), lorsque cette entité père subit une des opérations définies ci-dessus.
Prenons l'exemple suivant.
Exemple 14. Comportement cascade sur une relation
@OneToOne
@Entity public class Commune implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @OneToOne(cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Maire maire ; // reste de la classe }
Le comportement cascade est précisé par l'attribut
cascade, disponible sur les annotations :
@OneToOne,
@OneToMany et
@ManyToMany. La valeur de cet attribut est une énumération de type
CascadeType. En plus des valeurs
DETACH,
MERGE,
PERSIST,
REMOVE,
REFRESH, cette énumération définit la valeur
ALL, qui correspond à toutes les valeurs à la fois.
Remarquons bien que l'annotation
@ManyToOne ne définit pas cet attribut.
remove() de l'
entity manager
.
Dans l'exemple de nos communes et de nos maires, effacer une commune entraînera l'effacement du maire. Mais l'appel à
commune.setMaire(null) doit aussi entraîner l'effacement de ce maire, dans la mesure où cette entité sera orpheline.
On dispose pour cela d'un attribut défini sur
@OneToOne et
@OneToMany :
orphanRemoval. Le fait de mettre cet attribut à
true activera la détection d'entités orphelines, et leur effacement automatique.
Exemple 15. Effacement des orphelins sur une relation
@OneToOne
@Entity public class Commune implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @OneToOne(cascade={CascadeType.PERSIST, CascadeType.REMOVE} orphanRemoval=true) private Maire maire ; // reste de la classe }
José Paumard © 2018, tous droits réservés
- Introduction
- Un premier exemple
- Mettre un jeu de classes en base
- L'API Collection en base
- Héritage
- Requêtes
- EJB